
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 에다 부스트
- Mutex lock
- jdk #javac #jre #java standard library #javadoc #jar #java
- 운영체제
- 다항회귀
- 속성중요도
- db
- 코틀린
- JetBrains
- Java
- ML
- 11049
- featureimportances
- 머신러닝 #ml #선형대수학 #기본기
- Mutual exclusion
- gridsearch
- min-max
- featurescaling
- Kotlin
- 머신러닝 #ml #기본기
- ml
- 멀티 프로그래밍
- 지니불순도
- 디자인 패턴 #싱글톤
- 상호 배제
- bootstrapping
- 결정트리
- cross_val_score
- 경쟁 조건
- 머신러닝 #ml #미분 #기본기
- Today
- Total
코딩하는 오리
[ML] 머신 러닝, 더 빠르고 정확하게 - 2.정규화(Regularization) 본문
01. 편향(Bias)과 분산(Variance)
머신 러닝 모델이 정확한 예측을 못하는 경우
직선 모델은 너무 간단해서 복잡한 곡선 관계를 학습할 수 없다 -> 편향이 크다
모델이 데이터 사이의 관계를 완벽하게 학습했따 -> 편향이 작다
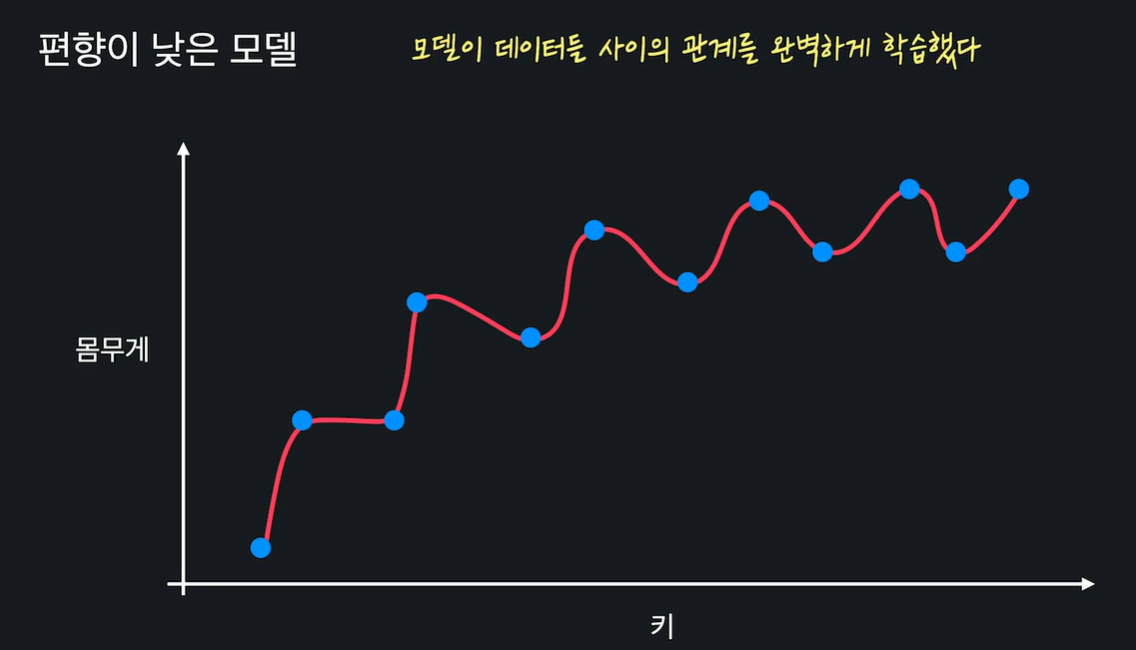
편향이 작으면 항상 좋나?
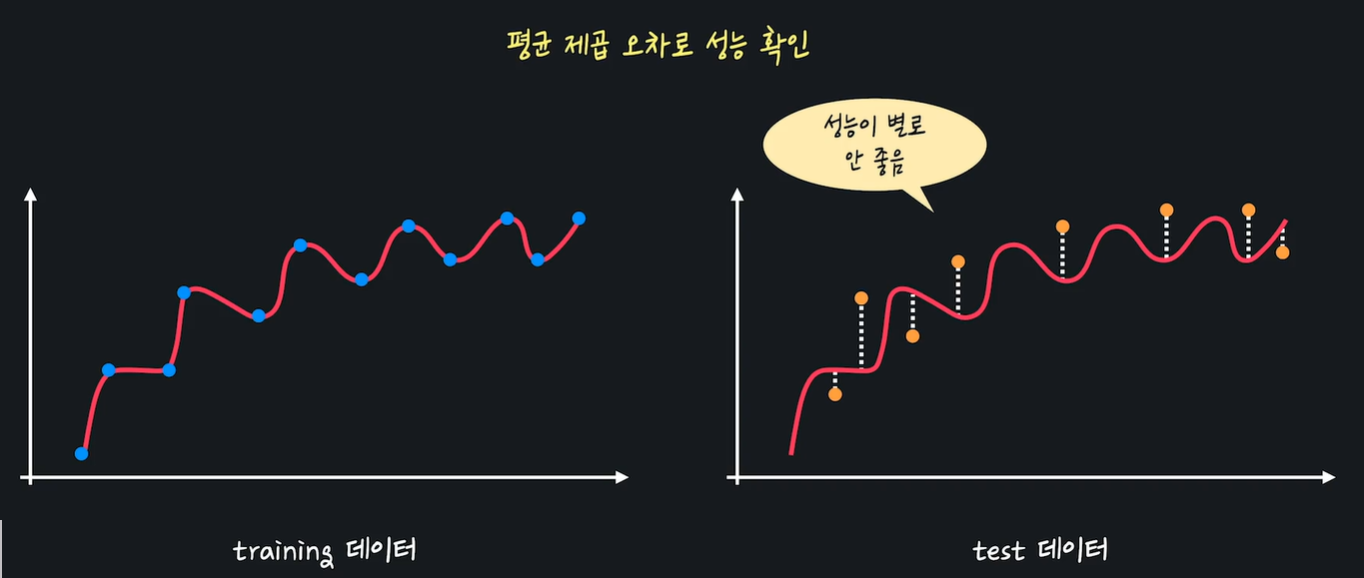
평균 제곱 오차로로 성능 구한다~
위의 경우에는 새로운 데이터에서 오히려 직선 보다 성능 안좋음..
외워버렸다
분산 : 데이터 셋 별(training set vs test set)로 모델이 얼마나 일관된 성능을 보여주는지
성능이 비슷하다 -> 분산이 낮다
성능이 들쭉날쭉 -> 분산이 높다
편향이 높은 모델은 너무 간단해서 주어진 데이터의 관계를 잘 학습하지 못한다(1차함수 vs 11차 함수)
편향이 낮은 모델은 주어진 데이터와의 관계를 잘 학습한다.
직선 모델은 편향이 높다(복잡도가 떨어져 곡선 관계를 학습할 수 없다)
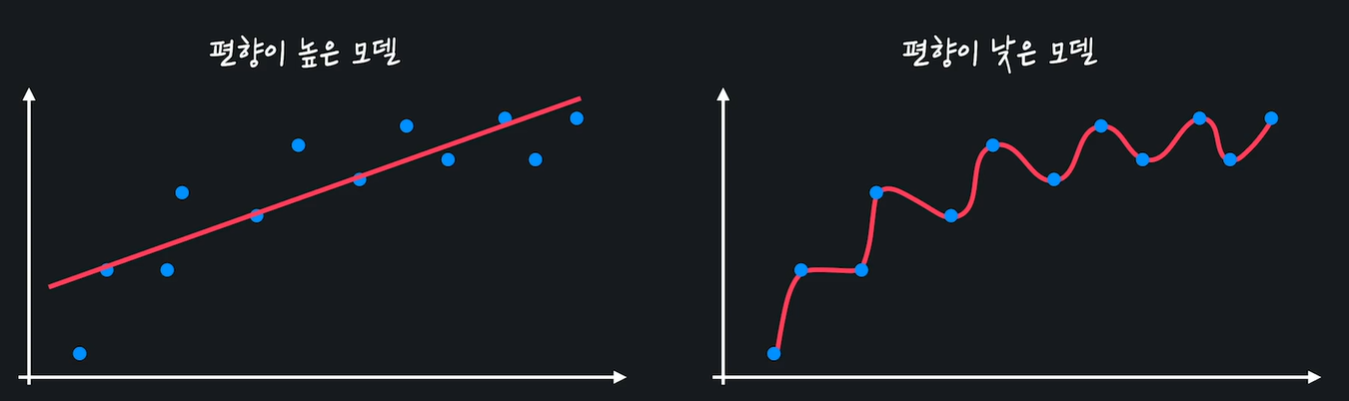
분산은 다양한 테스트 데이터가 주어졌을 때 모델의 성능이 얼마나 일관적인지 나타낸다.
직선 모델은 분산이 낮다

03. 편향-분산 트레이드 오프 (Bias-Variance Tradeoff)
편향이 높고 분산이 낮다 -> 과소적합(underfit) - 관계를 잘 나타내지 못함
편향이 낮고 분산이 높다 -> 과적합(overfit) - 관계를 너무 잘 나타냄
편향과 분산은 하나가 줄어들수록 하나는 늘어나는 관계
편황과 분산, 다르게는 과소적합과 과적합의 중간 balance를 찾아야~
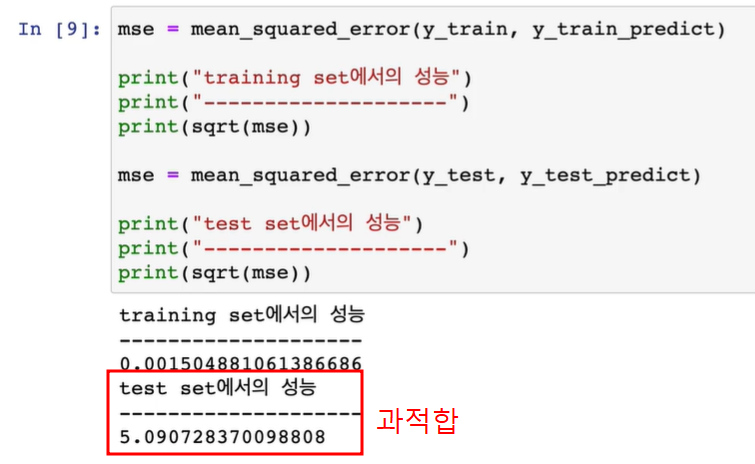
05. scikit-learn으로 과적합 문제 직접 보기

06. 정규화(Regularization) 개념
과적합된 모델은 함수가 굉장히 구불거려 training 데이터를 많이 통과한다
함수가 급격하게 변하는 이유는 세타 값들이 크기 때문 !
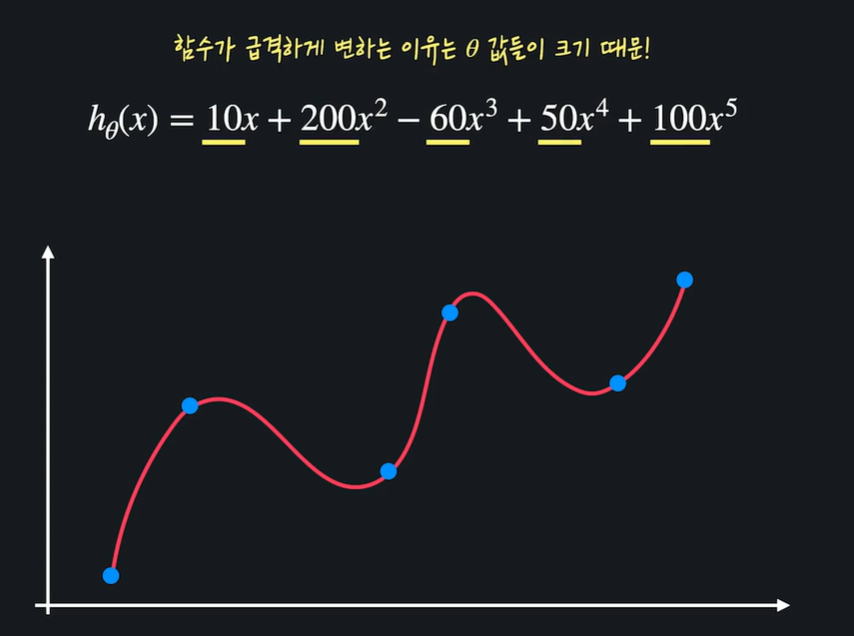
정규화 : 가설함수의 세타 값들이 너무 커지는 걸 방지해서 과적합을 예방하는 방법
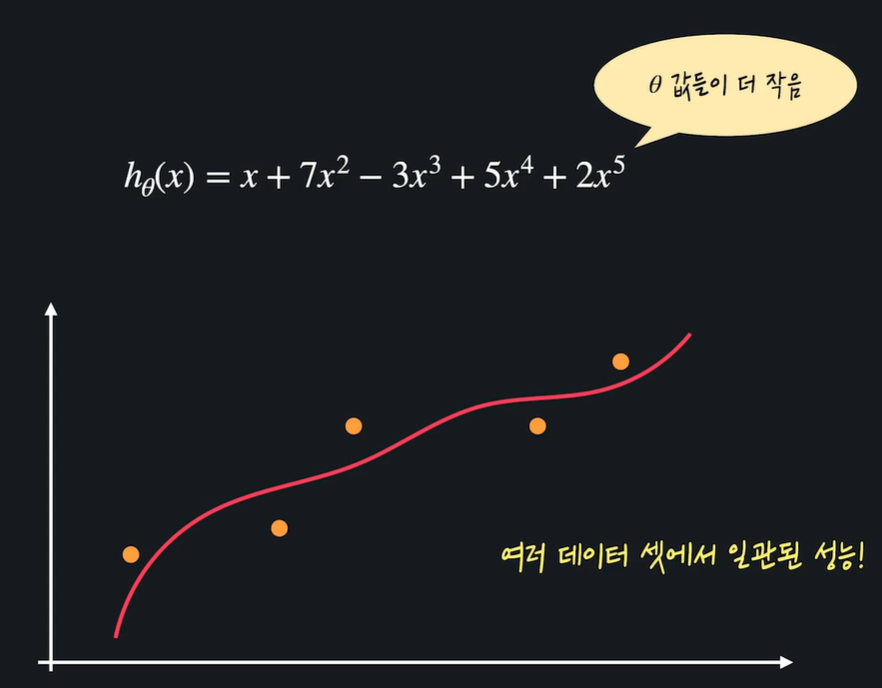
08. L1, L2 정규화
정규화 : 손실함수 + 정규화 항
손실함수 J

세타 값들이 너무 커서 성능이 별로...
training data에 대한 오차도 작고, 세타 값도 작아야지 좋은 가설함수다 !
즉 새로운 손실함수



위의 정규화 방법이 L1
L1 정규화를 적용한 회귀모델 : Lasso Regression (Lasso 모델)
L2 정규화

L2 정규화를 적용한 회귀 모델 : Ridge Regression (Ridge 모델)
람다가 클 수록 세타값 줄이는게 중요, 람다가 작을수록 데이터에 대한 오차를 줄이는게 중요
10. scikit-learn으로 과적합 문제 해결해보기
from sklearn.linear_model import Lasso
model = Lasso(alpha=0.001, max_iter=1000, normalize=True) : 람다를 0.001, 경사하강법 몇 번 할지, 모델 학습 전 인풋 데이터를 자동으로 0~1로 변환
model = Ridge(alpha=0.001, max_iter=1000, normalize=True)
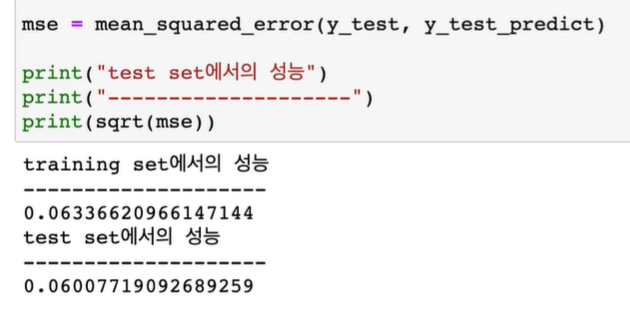
train 성능은 줄었지만, test 성능은 월등히 증가
13. L1, L2 정규화 일반화
로지스틱 회귀 모델을 구현한 LogisticRegression에 정규화를 적용하고 싶으면 어떻게 ?
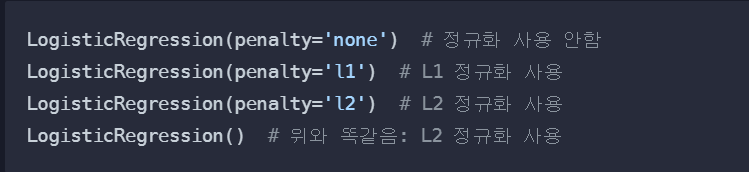
LogisticRegression은 사실 자동으로 L2 정규화를 적용한다(따라서 정규화를 적용하도록 따로 모델 안바꿔줘도 됨)
어떤 정규화 기법을 사용하는지 penalty라는 optional parameter로 정해줄 수 있다

14. L1, L2 정규화 차이점
L1정규화는 여러 세타값들을 0으로 만들어줍니다 모델에 중요하지 않는 속성들을 아예 없애버림
L2정규화는 세타값을 0으로 만들기보다는 조금씩 줄여준다. 모델에 사용되는 속성들을 L1처럼 없애지는 않음

L1정규화 : 어떤 모델에 쓰이는 속성, 변수의 갯수를 줄이고 싶을 때 사용
ex) 속성 20개를 사용해서 2차 다중 다항 회귀 모델 만들면 속성은 총 230개.. 속성이 많으면 과적합되고 학습시 많은 자원 소모할 수 있음. 이 때 L1정규화 사용 시 많은 세타를 0으로 만들어주어서 속성 갯수를 많이 줄일 수 있다.
L2 정규화 : 딱히 속성의 갯수를 줄일 필요가 없다고 생각되면 사용
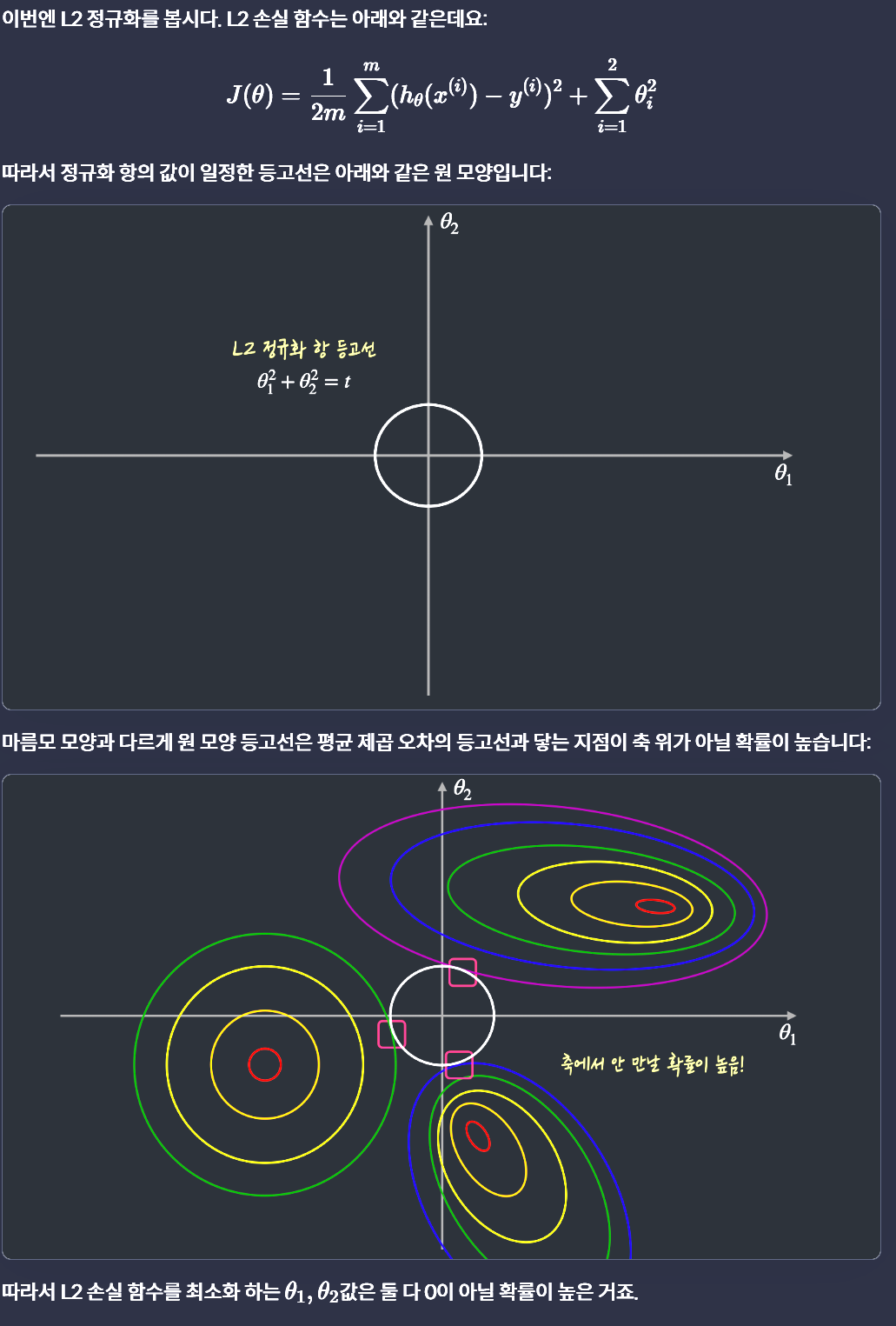
왜 L1정규화는 0을 만드나?


'AI > ML' 카테고리의 다른 글
| [ML] 머신 러닝, 더 빠르고 정확하게 - 3. 모델 평가와 하이퍼파라미터 고르기 (0) | 2024.07.31 |
|---|---|
| [ML] 머신 러닝, 더 빠르고 정확하게 - 1. 데이터 전처리 (0) | 2024.07.31 |
| [ML] 결정 트리와 앙상블 기법 - 03. 에다 부스트(Adaboost) (0) | 2024.07.31 |
| [ML] 결정 트리와 앙상블 기법 - 2. 랜덤 포레스트 (Random Forest) (0) | 2024.07.31 |
| [ML] 결정 트리와 앙상블 기법 - 1. 결정 트리(Decision Tree) (0) | 2024.07.30 |



