
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 속성중요도
- ML
- gridsearch
- 머신러닝 #ml #기본기
- 경쟁 조건
- ml
- 멀티 프로그래밍
- cross_val_score
- 다항회귀
- 11049
- 코틀린
- 머신러닝 #ml #미분 #기본기
- JetBrains
- 상호 배제
- db
- Mutex lock
- Kotlin
- Mutual exclusion
- Java
- min-max
- featureimportances
- 머신러닝 #ml #선형대수학 #기본기
- 디자인 패턴 #싱글톤
- 운영체제
- bootstrapping
- 에다 부스트
- 결정트리
- jdk #javac #jre #java standard library #javadoc #jar #java
- featurescaling
- 지니불순도
- Today
- Total
코딩하는 오리
[ML] 결정 트리와 앙상블 기법 - 1. 결정 트리(Decision Tree) 본문
01. 결정 트리란?
정의 : 질문들이 있고, 질문을 답해가면서 분류하는 알고리즘 !
예/아니오 질문들 + 이 질문들을 답해나가면서 분류하여 예측
ex) 교통 사고 생존 여부 분류
안전벨트를 했나요 ? => YES or NO
주행 속도가 시속 100km가 넘었나요 ? => ...
여러 질문들에 대해 순차적으로 답을 한다.
- 똑같은 속성에 하위 트리에서 다시 질문할 수 있다.
- 하나의 시작 질문에서 뻗어나간다.
- 질문 박스 하나하나를 노드
- 시작 질문은 루트 노드
- 마지막 예측값을 담은 것은 리프 노드
05. 지니 불순도 (Gini Impurity)
머신러닝에서 결정트리를 만들 때는 내용이 정해져있는게 아니라, 경험을 통해 직접 과정을 정해나가야한다.
데이터를 분류해보면서, 각 위치에서 어떤 노드가 제일 좋을지 골라야 한다.
선형 회귀의 알고리즘의 목적 : 학습 데이터를 가장 잘 나타낼 수 있는 일차식을 찾는 것
결정 트리의 목적 : 학습 데이터를 직접 분류해보면서, 데이터를 가장 잘 분류할 수 있는 노드를 찾아내는 것 !
이를 위해서는 어떻게 분류하거나 질문을 하는게 좋고, 안좋은지에 대한 기준,
전에 배웠던 손실함수 같은 개념이 필요하다.
결정 트리에서는 이를 지니 불순도를 통해서 한다.
정의 : 데이터 셋 안에서 서로 다른 분류들이 얼만큼 섞여있는지
지니 불순도는 데이터 셋이 얼마나 불순한지 숫자로 보여준다.

지니 불순도가 낮을수록 데이터는 순수하다(데이터들이 하나의 분류에 집중하고 있다 !)
가장 순수한 데이터는 지니 불순도가 0
딱 반이 독감, 반이 독감이 아닐 경우 => 0.5 높을 수록 불순도이다.
08. 분류 노드 평가하기
지니 불순도를 통해서 결정 트리의 노드를 정해보자

루트노드 만들기
선택지를 아래처럼 만들 수 있다. 바로 분류할 수도 있고, 질문 노드를 만들 수도 있다.
이 중에서 어떤 것을 골라야할 때 지니불순도를 활용한다.

좋은 분류 노드는 최대한 많은 학습 데이터 예측을 맞춘다 !
데이터 셋이 독감 데이터가 많을수록 좋다 !
데이터 셋이 순수할수록(지니 불순도가 낮을수록) 좋다 !

지금은 불순도가 꽤 높다 ! (독감과, 일반 감기 데이터가 많이 섞여있다..)
학습 데이터를 모두 독감으로 예측하면 40개를 틀려버린다...
10. 질문 노드 평가하기
만드려는 질문 노드가 얼마나 좋은지 평가하는 방법 !
결정 트리에서 좋은 질문은 데이터를 잘 나누는 질문이다.


질문으로 나뉜 데이터 셋이 순수할수록(지니 불순도가 낮을수록) 더 좋다 !
따라서 질문 노드의 성능을 평가할 때는 나뉜 두 데이터 셋에 지니 불순도를 사용한다.
각각 지니 불순도를 구한 다음, 가중치를 반영하여 평균을 내준다. (낮을수록 좋고, 높을수록 안 좋다)

12. 노드 고르기
여러 개의 분류, 질문 노드에서 어떤 것을 골라야할 지

분류 노드의 불순도가 가장 작으면 이미 데이터가 잘 나눠져 있기 때문에 있는 그대로 분류해도 된다는 뜻
질문 노드의 불순도가 가장 작으면 질문을 통해서 지금 있는 데이터 셋보다 불순도를 더 낮출 수 있다는 말
15. 모든 노드 만들기
다음 노드 만들기


몸살 있는 데이터 중에서 독감이 더 많으므로, 독감 분류 노드를 만들 수 있다.
이를 지니 불순도에 넣어보면 => 0.278

그 다음 노드도 가장 작은 지니 불순도 값을 질문 노드로 넣어주면 된다
트리의 맨 끝에 있는 leaf 노드들이 모두 분류 노드가 될 때까지 반복해 주면 결정 트리를 만들 수 있습니다.
특정 높이 이상 진행하지 않도록 최대 깊이 제한 할 수도 있다
17. 속성이 숫자형일 때 질문 노드
지금까지 속성은 참 거짓으로 바탕한 불린형 테이터였다.
데이터가 체온 처럼, 숫자형으로 있는 경우에는 만들 수 있는 질문이 엄청 많다.
체온이 37.1을 넘나요? 37.2를 넘나요 ? 등등... 끝없이 만들 수 있는데
하나의 속성에서 만들 수 있는 수많은 질문들 중, 하나를 고르는 법
1. 체온 데이터 정렬
2. 작은 순서대로 데이터 있을 때 각 연속된 체온 데이터의 평균을 계산
모든 체온 평균을 이용해서 질문을 하나씩 만든다. 모든 평균 체온에 대해서 지니 불순도를 계산
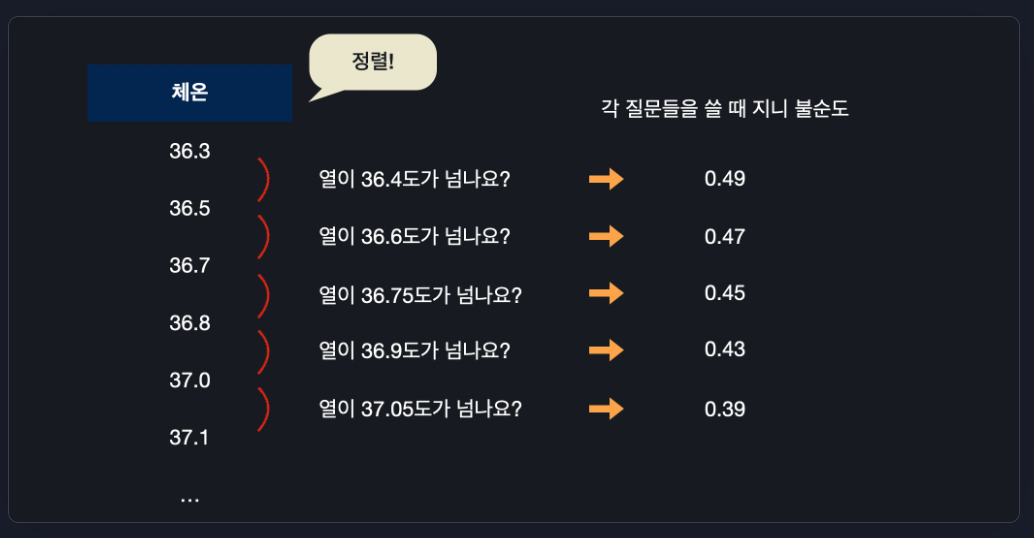
그러니까 “37.5가 넘나요?”, “몸살이 있나요?”, “기침이 있나요?” 이 세 질문과 “독감” 분류 노드들 중 가장 지니 불순도가 낮은 거를 선택하면 됩니다.
그리고 다음 노드를 만들 때도 자동으로 똑같이 체온 질문을 “37.5가 넘나요?”로 사용하는 건 아니고요. 매번 노드를 만들 때마다 위에서 했던 거처럼 해당 노드까지 오는 학습 데이터에 대해서 가장 좋은 체온 질문을 찾아내야 합니다.
이렇게 하면 데이터가 불린형이든 숫자형이든 상관 없이 결정 트리 노드들을 만들어 나갈 수 있습니다.
18. 속성 중요도 (Feature Importance)
결정 트리는 데이터를 분류하는 방법이 직관적, 쉽게 해석할 수 있는 장점이 있다.
쉽게 해석할 수 있다 = 어떤 속성이 중요하게 사용됐는지 알 수 있다.
만들어둔 트리에서 각 속성의 중요도를 파악해보자
노드 중요도(node importance)
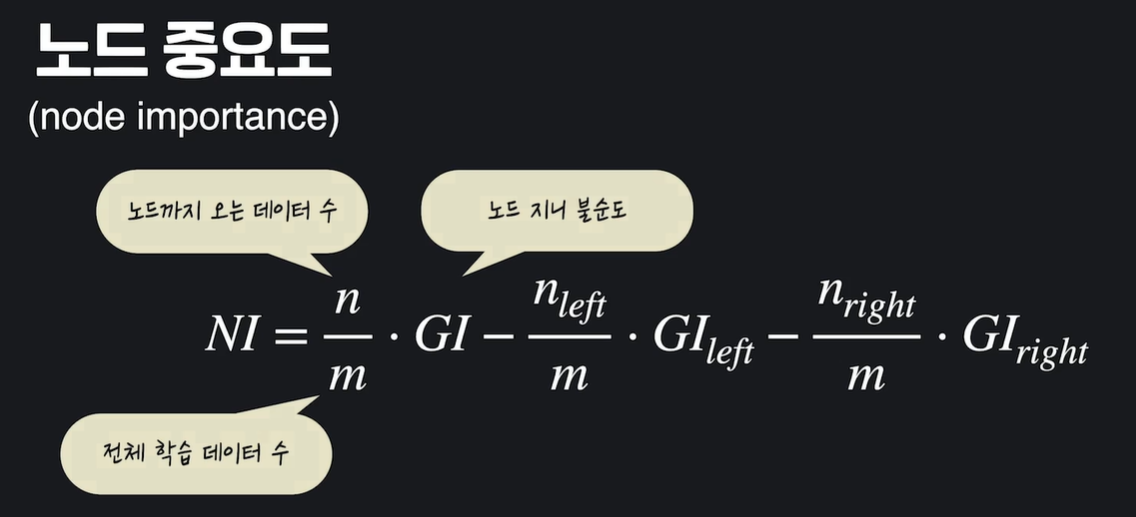

위 노드에서 아래 노드로 내려오면서, 불순도가 얼마나 줄어들었는지를 계산 !

이렇게 모든 질문 노드의 중요도를 계산한다 !

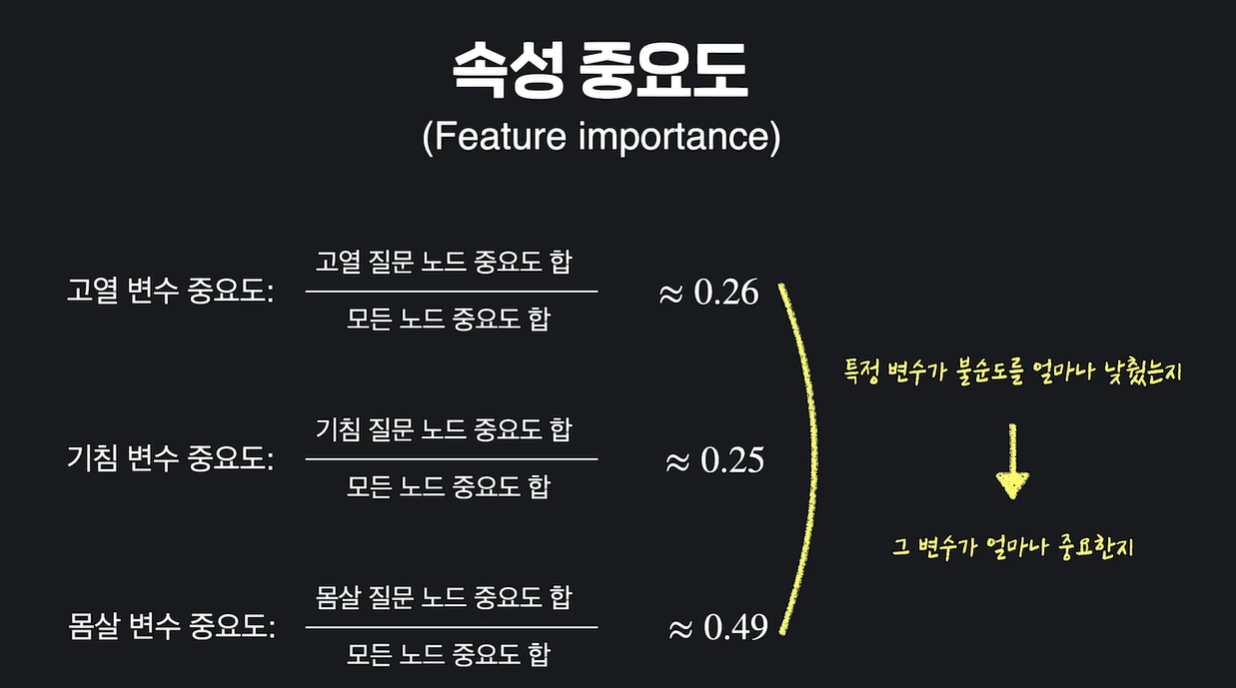
쉽게 생각하면, 모든 노드가 데이터를 양 갈래로 나누면서 나누는 데이터 셋들의 지니 불순도를 낮추는데요. 전체적으로 낮춰진 불순도에서, 특정 속성 하나가 낮춘 불순도가 얼마나 되는지를 계산한 겁니다.
특정 속성을 질문으로 갖는 노드들의 중요도의 평균을 구한 거랑 비슷한데요. 그렇기 때문에 이렇게 최종적으로 구한 값을 속성의 평균 지니 감소 (Mean Gini decrease)라고 부르기도 합니다.
각 속성의 평균 지니 감소를 이용하면, 특정 속성이 결정 트리 안에서 평균적으로 얼마나 불순도를 낮췄는지를 계산할 수 있고, 이게 있으면 결정 트리 안에서 그 속성이 얼마나 중요한지를 판단할 수 있는 거죠.
20. scikit-learn 데이터 준비하기
X = pd.DataFrame(iris_data.data, columns=iris_data.feature_names)
y = pd.DataFrame(iris_data.target, columns = ['class'])
21. scikit-learn으로 결정 트리 쉽게 사용하기
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier(max_depth=4)
model.fit(X_train, y_train)
y_test_predict = model.predict(X_test)
model.score(X_test, y_test)
0.9 : 약 90%의 확률로 제대로 분류한다는 뜻
22. scikit-learn으로 속성 중요도 확인하기
모델을 학습 시키면 자동으로 model.feature_importances_ 에 중요도가 저장된다
import matplotlib.pyplot as plt
import numpy as np
importances = model.feature_importances_


붓꽃 꽃잎 길이가 가장 중요하게 사용됨 !
'AI > ML' 카테고리의 다른 글
| [ML] 결정 트리와 앙상블 기법 - 03. 에다 부스트(Adaboost) (0) | 2024.07.31 |
|---|---|
| [ML] 결정 트리와 앙상블 기법 - 2. 랜덤 포레스트 (Random Forest) (0) | 2024.07.31 |
| [ML] 기본 지도 학습 알고리즘들 - 4. 로지스틱 회귀 (Logistic Regression) (0) | 2024.07.30 |
| [ML] 기본 지도 학습 알고리즘들 - 3. 다항 회귀 (Polynomial Regression) (0) | 2024.07.30 |
| [ML] 기본 지도 학습 알고리즘들 - 2. 다중 선형 회귀(Multiple Linear Regression) (0) | 2024.07.29 |



