[ML] 결정 트리와 앙상블 기법 - 03. 에다 부스트(Adaboost)
01. Boosting
~전보다 더 크거나 높게 하다 !
일부러 성능이 안 좋은 모델들을 사용한다.
먼저 만든 모델들의 성능이 뒤에 있는 모델이 사용할 데이터 셋을 바꾼다
모델들의 예측을 종합할 때, 성능이 좋은 모델의 예측을 더 반영한다
핵심 : 성능이 안 좋은 약한 학습자(weak learner)들을 합쳐서 성능을 극대화 한다 !
02. 에다 부스트(Adaboost) 개요
에다 부스트에서는 랜덤 포레스트에서처럼 깊은 결정 트리가 아니라
루트 1개와 분류 노드 2개를 갖는 얕은 결정 트리를 만든다(단순).

성능 : 평균적으로 50%보다 조금 좋은 성능을 낸다
일부러 일반 결정트리가 아닌 스텀프를 사용한다.
+ 부스팅 기법 답게 각 모델이 사용하는 데이터 셋을 임의로 만들지 않는다
앞에 있는 스텀프가 틀린 애들의 중요도를 좀더 높여주고
맞게 예측한 데이터의 중요도를 낮춰준다.
중요도가 높은 데이터들은 뒤에 만들 스텀프들이 더 우선적으로 맞출 수 있게 한다.
중요도가 낮은 데이터들은 좀 덜 신경쓰게 해준다.
-> 전에 예측에 틀렸던 데이터들을 좀 더 잘 예측하는 스텀프를 만드는 것
뒤 스텀프들은 앞 스텀프들의 실수를 더 잘 맞추게 된다 ~
100개, 150개, 200개의 스텀프를 만들어둔다.
에다 부스트는 다수결의 원칙이 아니라 성능 주의적 예측으로 한다.
ex) 스텀프의 갯수가 반반이어도 성능의 합에 따라 결정

에다 부스트
- 성능이 좋지 않은 결정 스텀프를 많이 만든다(weak learners)
- 각 스텀프는 전에 왔던 스텀프들이 틀린 데이터들을 더 중요하게 맞춘다
- 예측을 종합할 때, 성능이 좋은 스텀프의 의견 비중을 더 높게 반영한다.
04. 스텀프 성능 계산하기
에다 부스트는 전에 있는 스텀프들이 틀리게 예측한 데이터들을 조금 더 잘 맞추려고 하는 알고리즘이잖아요?
그렇기 때문에 스텀프를 만들 때 전에 예측에 실패했던 데이터들을, 조금 더 중요하게 취급을 해야 되는데요.
이걸 수치화하고 보기 편하게 그냥 여기 열로 추가시켜주는 거죠.
처음에는 틀리게 예측한 데이터가 없으니까 모든 데이터의 중요도를 같게 설정합니다.
7개의 데이터가 있으니까 각각 1/7… 씩 이렇게요. 중요도의 합은 항상 1로 유지시켜줍니다.


매번 스텀프를 만들 때 성능을 계산해야 한다.
첫 스텀프는 전에 만든 스텀프가 없기 때문에 결정 트리 만들 때와 똑같이 루트 노드를 고른다
(즉, 각 질문들의 지니불순도를 계산하여, 지니불순도가 가장 낮은 질문을 기준으로 정함)

왜 저 식을 스텀프 성능 구할 때 쓸까?

저 그래프 모양을 보면 total_error이 1(틀리게 예측)일 때 성능을 엄청 작게 만들어주고
total_error가 0일 때 성능을 극대화 해준다
total_error가 0.5일 때는 성능이 의미가 없으니까 결과는 0
스텀프의 생성과 성능
- 첫 번째 스텀프는 결정 트리를 만들 때처럼 지니 불순도를 써서 만든다.
- 모든 데이터에는 중요도가 있다. 중요도는 total_error를 계산하는데 사용한다.
- total_error를 이용하면 스텀프의 성능을 계산할 수 있다.
06. 데이터 중요도 바꾸기
현재 모든 데이터 중요도는 1/7
중요도가 높은 데이터를 더 잘맞추게 할 것이다.
틀린 데이터는 중요도를 높이고, 맞은 데이터 중요도를 낮춘다.
Ptree 값은 스텀프의 성능..
스텀프가 반 이상 맞추면 성능이 0보다 크고
스텀프가 반보다 못 맞추면 성능이 0보다 작다
왼쪽 : 틀리면 1보다 큰 값 곱하여 중요도 높아짐
오른쪽 : 맞으면 1보다 작은 값 곱하여 중요도 낮아짐
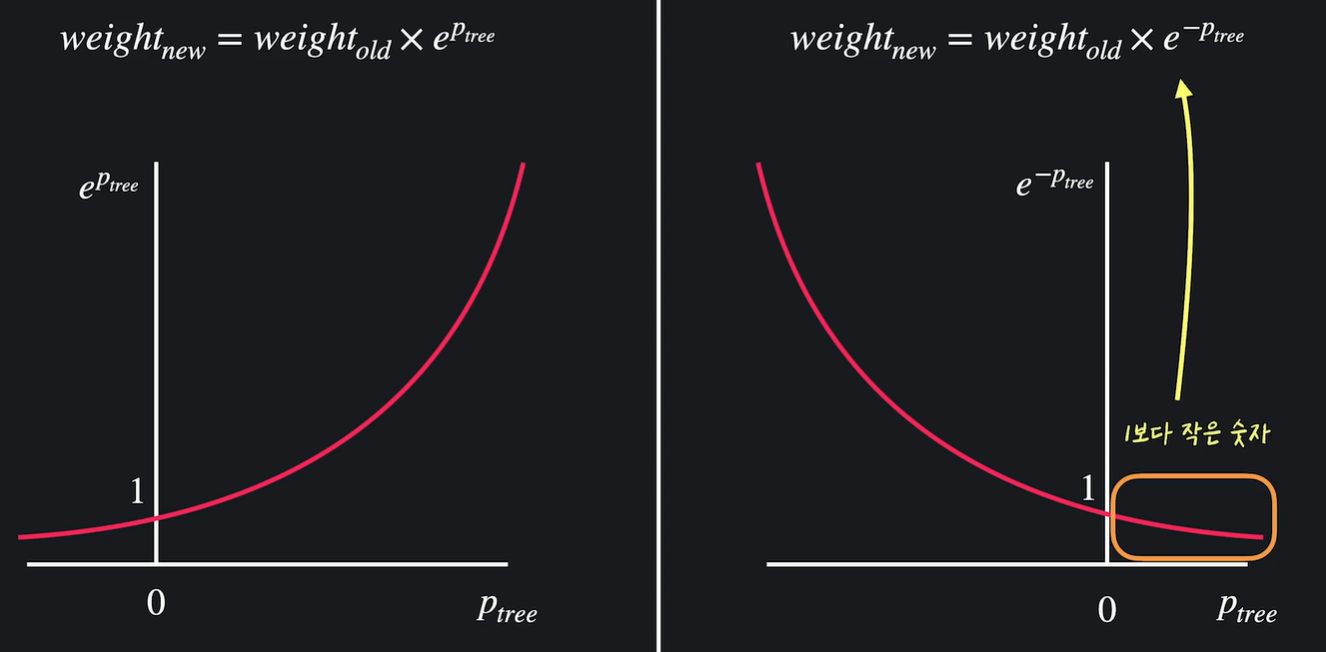
항상 중요도의 합이 1이 되게 하기 위해서 처리 필요

08. 스텀프 추가하기
새로 만들 데이터 셋은 기존 데이터 셋의 중요도를 반영한 확률을 반영하여 만든다.
중요도 값에 대한 범위를 만들어 임의로 뽑은 숫자가 포함될 경우 데이터 선택
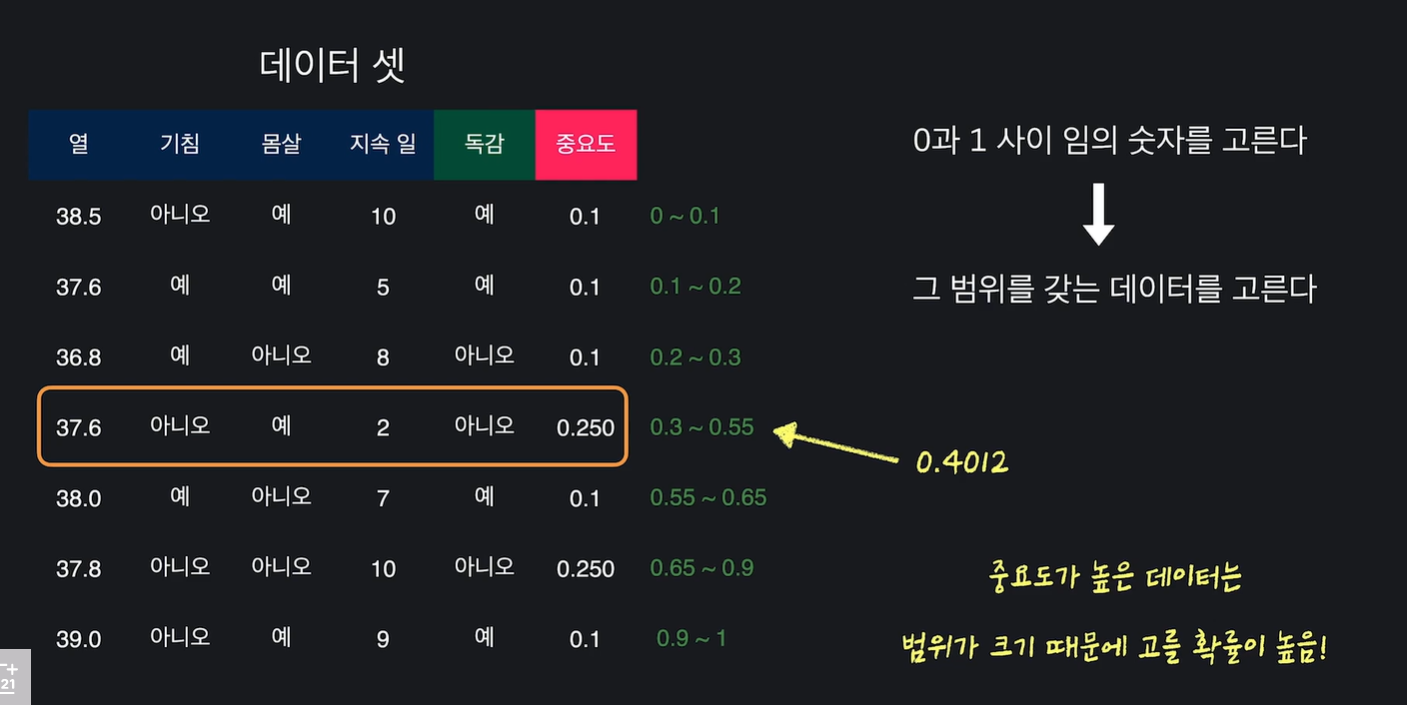

새로운 데이터 셋에서 스텀프를 만들고 스텀프의 성능을 계산한다 ~
스텀프의 생성과 성능
- 전 모델의 틀린 데이터의 중요도는 올렸고, 맞은 데이터의 중요도는 낮췄다.
- 중요도를 이용해서 새로운 스텀프가 사용할 데이터 셋을 만들었다.
- 새로운 데이터 셋으로 스텀프를 학습시켜 추가했다.
10. 예측하기
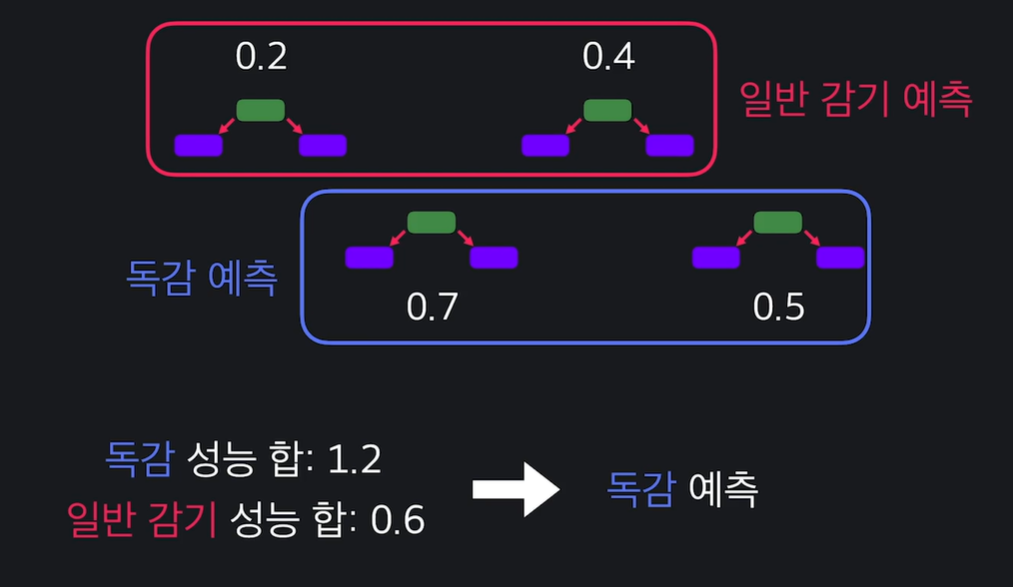
에다 부스트 예측
수많은 스텀프가 있어도 동일 ! 스텀프의 성능의 합이 더 큰 결정을 선택
11. scikit-learn으로 에다 부스트 쉽게 사용하기
from sklearn.ensemble import AdaBoostClassifier
model = AdaBoostClassifier(n_estimators=100) : 결정 스탬프 몇 개 만들지
model.feature_importances_ -> 시각화 가능